Abstract
Estimating full-hand grasp pressure from egocentric video is critical for immersive VR and robotic manipulation, yet dense tactile sensing often relies on intrusive hardware. Existing vision-based methods predominantly rely on planar surfaces or fingertip contacts, failing to generalize to complex 3D object interactions. Therefore, we introduce EgoTactile, a benchmark pairing egocentric video with full-hand pressure supervision for diverse everyday objects, incorporating a bare-hand transfer subset to enable generalization to natural scenarios. Leveraging this benchmark, we first establish EgoPressureFormer as a discriminative baseline. Beyond this, to explicitly address the uncertainty in partial observations, we propose EgoPressureDiff, a conditional diffusion framework that adapts a large-scale pre-trained video diffusion backbone. By combining rich world knowledge priors with a Physically-Informed Feature Rectification layer to inject semantic constraints, our approach effectively hallucinates plausible contact patterns and resolves visual-physical ambiguities. Extensive experiments demonstrate that our method achieves superior performance on the benchmark and robust transferability to in-the-wild scenarios.
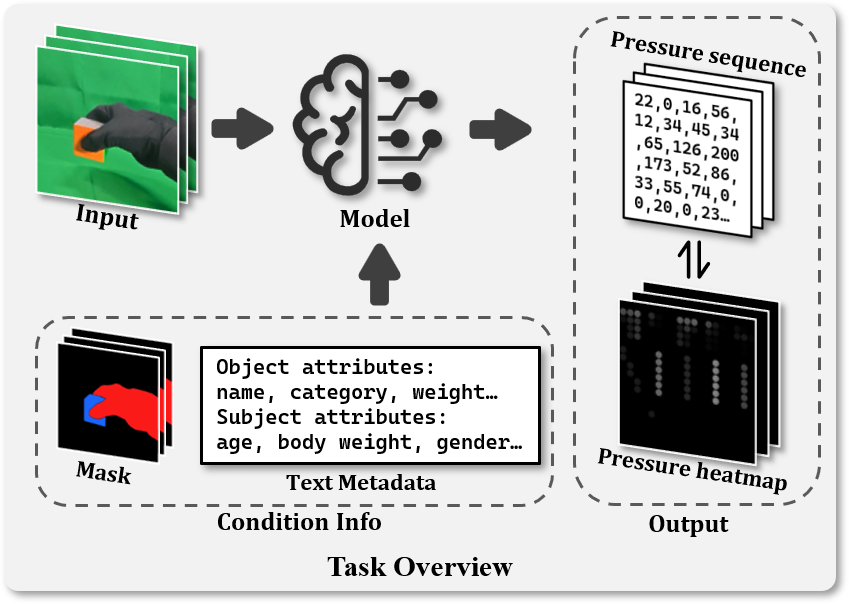
Figure 1: Task overview. Given an input RGB clip, the model predicts a pressure sequence or heatmap, optionally leveraging auxiliary Condition Info (e.g., masks and text metadata) to resolve physical ambiguities. The output is represented in two inter-convertible formats: a sparse sensor sequence and a dense spatial heatmap.